


In today's data-driven era, computing power has indeed become the key to driving technological progress. In the past, computing power mainly relied on the CPU (central processing unit), but with the explosive growth of data scale, the demand for computing speed and processing power has also surged. The emergence of GPU (Graphics Processing Unit), especially empowered by NVIDIA CUDA technology, has opened up new fields for high-performance computing.
What is CUDA?

CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model developed by NVIDIA Corporation. It allows developers to leverage the parallel processing capabilities of GPUs, significantly improving computational efficiency, especially when dealing with large-scale datasets and complex computing tasks. The introduction of CUDA enables GPUs not only to handle graphics rendering tasks, but also to be widely applied in various fields such as scientific computing, machine learning, artificial intelligence, and data analysis.
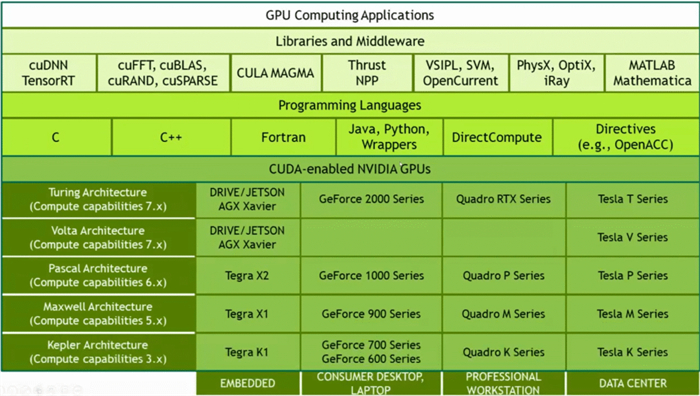
The cornerstone of Nvidia's software ecosystem
CUDA is the solid foundation of Nvidia's software ecosystem. Through CUDA, Nvidia not only provides developers with a complete software development kit (SDK), but also supports a range of advanced technology solutions developed based on the CUDA platform, such as TensorRT, Triton, and Deepstream.
TensorRT is a high-performance deep learning inference optimizer and runtime library that can deploy optimized models to GPUs for fast and efficient inference performance. TensorRT supports model import for various deep learning frameworks, such as TensorFlow, PyTorch, etc., simplifying the complexity of model deployment.
Triton inference server is a flexible inference service framework that allows developers to run multiple models simultaneously on a server and dynamically schedule them based on request priority and model performance. Triton has improved the efficiency and response speed of the overall inference service by optimizing the loading and execution time of the model.
Deepstream is a real-time video processing framework that utilizes GPU acceleration to handle computer vision tasks in real-time video streams, such as object detection, facial recognition, behavior analysis, and more. Deepstream provides a complete set of APIs and toolkits, simplifying the development process of video processing applications.
They are all technology solutions developed based on the CUDA platform, demonstrating the powerful driving force of CUDA in promoting software innovation.
The perfect combination of hardware and software
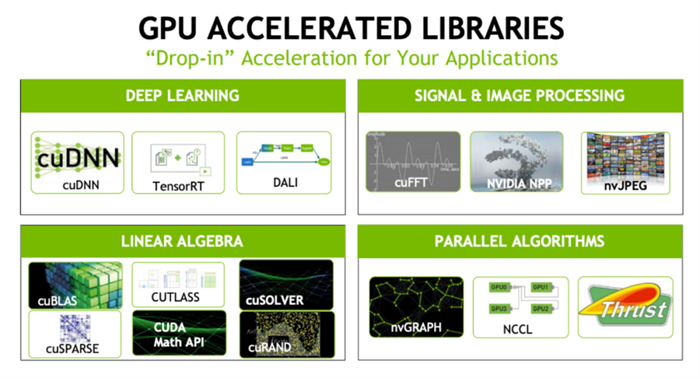
NVIDIA GPUs are renowned for their outstanding performance, but to fully unleash the enormous potential of this hardware, software support that complements it is essential. CUDA is such a key software that provides developers with a powerful interface platform. Through CUDA, developers can delve into the deep capabilities of GPUs to achieve efficient computing and acceleration tasks.
CUDA is like a highly skilled racing driver who knows the vehicle like the back of his hand and can precisely control every detail. It ensures the maximum release of GPU hardware performance, allowing each computation to reach its optimal state. With the help of CUDA, developers can decompose complex computing tasks into units suitable for GPU parallel processing, greatly improving computing efficiency and meeting the growing demand for high-performance computing. The close integration of software and hardware enables Nvidia GPUs to demonstrate unparalleled strength in various fields such as scientific simulation, big data processing, machine learning, and more.

Acceleration engine for deep learning
CUDA plays a crucial role in the cutting-edge field of deep learning. It not only greatly promotes the construction of Nvidia's own software ecosystem, but also injects strong impetus into the prosperity of third-party software ecosystems. In widely used deep learning frameworks such as PyTorch and TensorFlow, CUDA's acceleration feature has become standard, allowing developers to easily configure and use it, thereby achieving fast and efficient model training and inference operations, greatly improving computational efficiency.
CPU and GPU: The Twin Swords of Computing
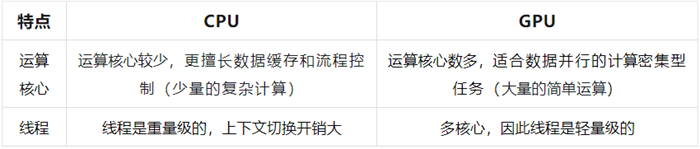
The CPU (central processing unit) is the center of a computer system, and its function is equivalent to the "brain" of the entire system. As a core component, the CPU is responsible for executing instructions, processing data, and managing the system's operations and control flow. Despite having a relatively small number of cores, the CPU performs well in executing complex logical operations and controlling intensive tasks. Its powerful data caching and flow control capabilities make it an ideal choice for handling highly complex computing tasks, although few in number.
GPU (Graphics Processing Unit) is known for its large number of computational cores, originally designed primarily for graphics and visual data processing. However, with the rapid development of deep learning and artificial intelligence technologies, the parallel computing power of GPUs has been widely applied. In the field of AI, the computing efficiency of GPUs has significantly improved, making them the preferred choice for data intensive tasks, especially in scenarios that require a large amount of parallel computing. GPUs can greatly accelerate the training and inference process, becoming a superstar in the field of data processing.
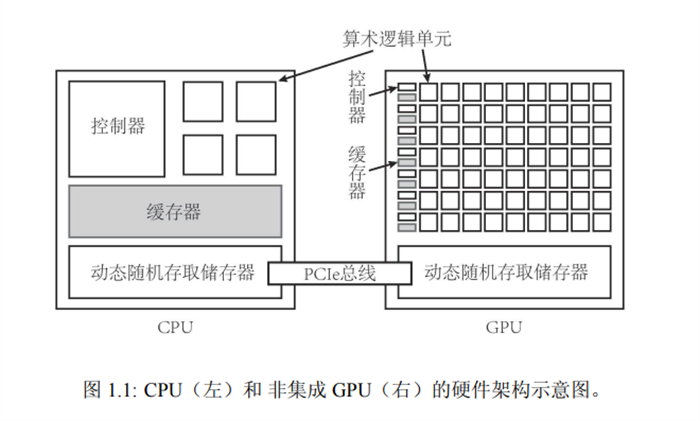
The Power of Parallel Computing
The CPU (central processing unit) is like an elite special forces unit, with a small number of members but each possessing unique skills that can quickly respond to and handle complex tasks. These cores are carefully designed to perform computational tasks that require precise operations and meticulous strategic planning.
GPU (Graphics Processing Unit) is more like a massive army, consisting of hundreds or even thousands of cores. Although the computing speed of a single core may not be as fast as a CPU, they excel at collaborative operations, executing large-scale tasks through parallel computing. It is this design that enables GPUs to demonstrate stronger computing power than traditional CPUs in handling tasks that require a large amount of repetitive computation, such as graphics rendering, scientific computing, and machine learning algorithms.
With the help of the CUDA programming framework, developers are like clever commanders, able to accurately command the efficient flow of data among the numerous cores of the GPU, and coordinate the collective actions of these cores to jointly solve complex computational problems.
In the constructed heterogeneous computing platform, the CPU and GPU form a special cooperative relationship.
For example, GPU (Graphics Processing Unit) is not a lone warrior, but a powerful assistant to CPU (Central Processing Unit), working together on the battlefield of computing. In this collaborative mode, the CPU plays the role of a commander, responsible for scheduling and coordinating tasks, while the GPU acts as an executor, accelerating the completion of specific computing tasks with its powerful parallel processing capabilities.

Aisdak always adheres to customer needs as the core, driven by intelligent equipment and precision technology, industrial software connects data flow, data+AI algorithm empowers smart warehousing in the electronics and semiconductor industries, focuses on product quality, and serves with dedication. Aisdak helps enterprises solve practical problems encountered in the scientific, standardized, digital, automated, and intelligent upgrading of intelligent warehousing, and provides customized services for intelligent warehousing equipment. In the future, AstraZeneca will continue to leverage its advantages in technical talent and resources to contribute to the transformation and upgrading of the manufacturing industry.
